[정리] Scalable Second Oder Optimization for Deep Learning (2021)
06 Apr 2022Author: Rohan Anil, Vineet Gupta, Tomer Koren, Kevin Regan, Yoram Singer
Paper Link: https://arxiv.org/abs/2002.09018
Code: https://github.com/google-research/google-research/tree/master/scalable_shampoo
 (image from here)
(image from here)
요약
AdaGrad 를 확장한 preconditioner 이용 최적화 방법인 Shampoo의 계산 속도를 개선하는 방법을 제안함. 각 레이어 별 preconditioner 연산을 병렬화하는 방법과 행렬을 여러 블락들로 근사하는 방법을 이용함. Machine translation, Image classification 같은 문제들에서 큰 계산 시간 증가 없이 더 좋은 성능과 빠른 수렴을 보임.
0 Abstract
- 1차 경사 하강법에 비해 2차 최적화 방법은 계산량, 통신량이 많고 메모리 소모가 커 잘 사용되지 않았음
- 큰 스케일 문제에 사용될 수 있는 2차 preconditioned method 를 제안함
- 높은 수렴성과 1차 경사 하강법 대비 wall-clock 기준 빠른 업데이트를 확인함
- 여러 CPU 와 가속기(GPU, TPU)를 활용한 결과로, BERT, ImageNet 같은 큰 학습 문제에서 성능 확인함
1 Introduction
- 2차 방법에서 계산량과 메모리 소모를 줄이는 것이 중요하며, 학습에 필요한 스텝 수를 줄일 수 있음
- 확률 최적화를 위한 적응형 방법을 제안하며, AdaGrad, Adam 의 full matrix 버전이라 할 수 있고 parameter 사이 correlation 을 고려하게 됨 (이 방법들은 gradients 의 외적합을 이용하여 2차 모멘트 행렬을 계산했음)
- 2차 방법의 문제점들을 완화하기 위해 K-FAC, K-BFGS, Shampoo 가 제안되었지만, 큰 스케일의 딥러닝을 위해 병렬화하기 어려움
1.1 Contribution
- 많은 레이어들을 갖는 딥러닝 모델을 학습하기 위해 Shampoo 방법을 확장하였음
- Preconditioner 행렬을 위해 계산량이 많은 SVD 을 PSD 행렬을 위한 안정적인 방법으로 대체함
- Machine translation, Language modeling 등에서 학습 속도 (Wall-clock) 향상을 확인하였음
1.2 Related Work
- Bollapragada et al., 2018 은 노이즈가 적은 Full batch L-BFGS 와 확률 경사 사이의 방법을 제안함
- 대부분의 이전 Preconditioner 방법은 대각 행렬 근사를 이용하였으나, 최근에 들어 full matrix 를 이용하는 방법들이 제안되었음
- K-FAC 은 Fisher 행렬을 근사하여 preconditioner 로 사용하는 것이며, K-BFGS 는 레이어의 Hessian 을 유사한 방법으로 근사함
- GGT 는 AdaGrad preconditioner 를 row-rank 근사하는 방식이나 많은 수의 gradients 를 저장해야므로 중간 정도 크기의 모델에 적합함
- Ba et al., 2017 은 K-FAC 의 distributed 버전을 제안했음
2 Preliminaries
Notation
-
Frobenius norm of A: $ A ^2F=\sum{i,j}A^2_{i,j}$ - Element-wise product of A and B: $C=A\bullet B\iff C_{i,j}=A_{i,j}B_{i,j}$
- Element-wise power: $(D^{\odot\alpha}){i,j}=D^{\alpha}{i,j}$
- $A\preceq B$ iff $B-A$ is positive semi-definite (PSD)
- For a symmentric PSD matrix $A=UDU^\text{T}$, $A^\alpha=UD^\alpha U^\text{T}$
- Identities of the Kronecker product of A and B:
- $(A\otimes B)^\alpha=A^\alpha\otimes B^\alpha$
- $(A\otimes B)\mathbf{vec}(C)=\mathbf{vec}(ACB^\text{T})$
Adaptive preconditioning methods
- Parameter $w_t\in\mathbb{R}^d$ 는 gradient $\bar{g}_t\in\mathbb{R}^d$ 와 precondition 행렬 $P_t\in\mathbb{R}^{d\times d}$ 에 대해 다음과 같이 업데이트됨 \(w_{t+1}=w_t-P_t\bar{g}_t\)
- $P_t$ 는 2차 최적화 방법에서 Hessian 행렬이 되지만, adaptive preconditioning 방법에서는 gradients 의 correlation 과 관련됨
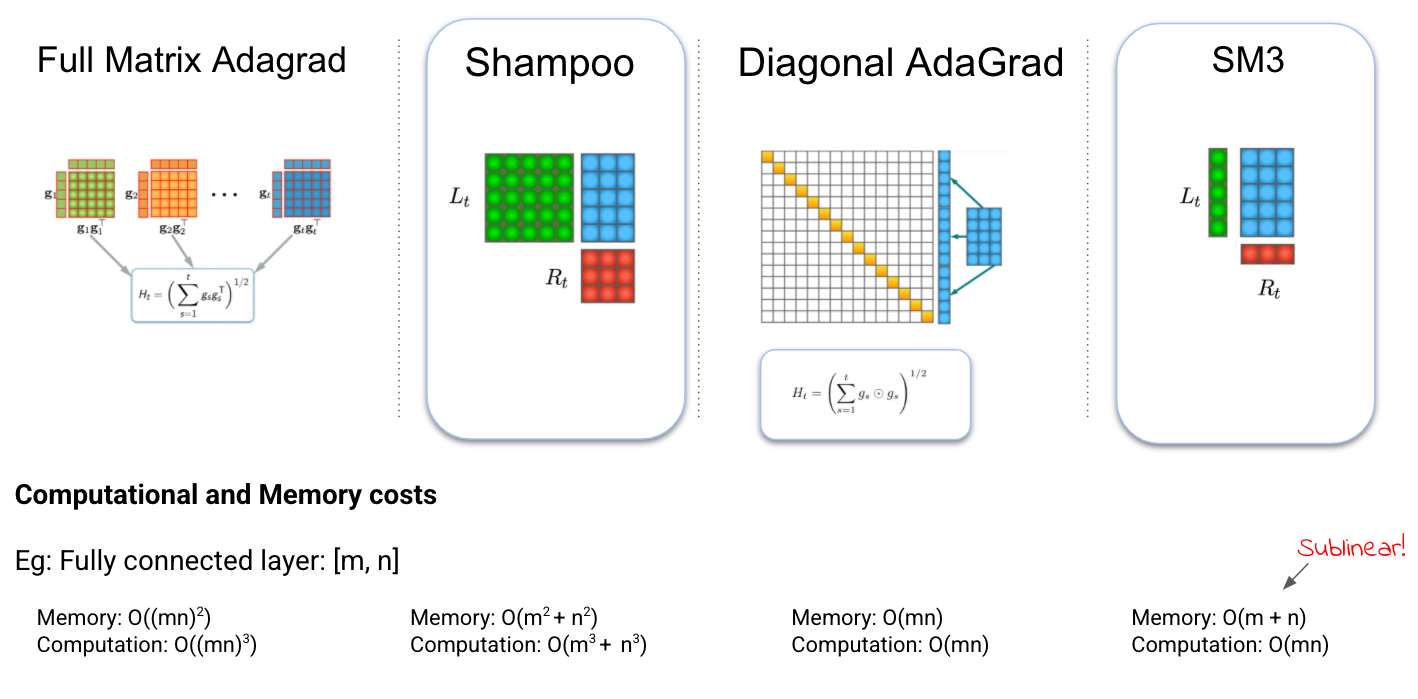
- Parameter 와 gradient 를 행렬 $W, G \in\mathbb{R}^{m\times n}$ 로 각각 표현 했을 때, full matrix 일 경우의 precondition 의 저장공간은 $n^2m^2$ 만큼 필요하며, 업데이트 식의 계산량은 $m^3n^3$ 이므로 근사 없이는 계산이 불가능함
The Shampoo algorithm
- Shampoo 는 Kronecker product 를 이용하여 대각행렬 근사 방법과 full matrix 방법을 잇는 방법임
- Iteration $t$ 의 손실 함수에 대한 gradient $G_t=\nabla_Wl(f(W,x_t),y_t)$ 에 대해 $L_t\in\mathbb{R}^{m\times m}$ 와 $R_t\in\mathbb{R}^{n\times n}$ 는 아래같이 정의됨 \(L_t=\epsilon I_m+\textstyle\sum^t_{s=1}G_sG_s^{\text{T}} \quad R_t=\epsilon I_n+\textstyle\sum^t_{s=1}G_s^{\text{T}}G_s\)
- Full matrix Adagrad preconditioner $H_t$ 는 $(L_t\otimes R_t)^{1/2}$ 로 근사되며, Adagrad 의 업데이트 방식인 $w_{t+1}=w_t-\eta H_t^{-1/2}g_t$ 을 따라 Shampoo 의 업데이트 식은 아래와 같음 \(W_{t+1}=W_t-\eta L_t^{-1/4}G_tR_t^{-1/4}\)
3 Scaling-up Second Order Optimization
적은 연산량과 메모리 소모를 보이는 1차 방법보다 Shampoo 는 (1) Preconditioner 계산 (2) 역행렬 계산 (3) 행렬 곱 계산이 추가됨 이 중에서도 역행렬 계산을 으로 인한 학습 속도 저하를 최소화하는 것이 가장 중요함
3.1 Preconditioning of large layers
Large Layers
다음 Lemma 1 에 따라 full Adagrad precondition $\hat{H}_t$ 의 근사 방법 중 $L_t^{1/p}\otimes R_t$ 을 사용함 (Theorem 3 에서 regret bound 확인)
Lemma 1. 최대 rank () $r$ 인 행렬들 $G_1, …, G_t\in\mathbb{R}^{m\times n}$, $g_s=\mathtt{vec}(G_s)$ 에 대해 $\hat{H}t=\epsilon I{mn}+\textstyle\sum^t_{s=1}g_sg_s^\text{T}$ 를 정의하자. 위에서 정의한 $L_t, R_t$ 와 $1/p+1/q=1$ 을 만족하는 $p, q$ 에 대해 $\hat{H}_t\preceq rL_t^{1/p}\otimes R_t^{1/q}$ 이다.
Preconditioning blocks from large tensors
여러 레이어들의 경우에 계산량 및 메모리 소모를 줄이기 위해 각 레이어에 해당하는 텐서 블락을 분리함
Lemma 2. 벡터 $g_1, …, g_t\in\mathbb{R}^{mk}$ 에 대해 $g_i=[g_{i,1},…,g_{i,k}]$ 이고 $g_{i,j}\in\mathbb{R}^m$ 일 대, $B^{(j)}t=\epsilon I_m +\textstyle\sum^t{s=1}g_{s,j}g_{s,j}^\text{T}$ 이도록 $B_t$ 를 정의하면, $\hat{H}_t\preceq{kB_t}$ 이다.
Delayed preconditioners
Precondition 행렬은 수 백의 스텝마다 업데이트되더라도 성능에 큰 영향을 주지 않았으며 (Fig. 4c), 이는 손실 함수의 landscape 이 꽤 평탄함을 의미하고 성능과 계산 속도가 상충 관계임을 뜻함
3.2 Roots of ill-conditioned matrices
행렬의 interse pth root, 즉 $A^{-1/p}$ 를 구할 때 계산량이 많은 SVD 보다 효율적인 coupled Newton iteration 방법을 사용할 수 있음 (Fig. 7) 또한 $L_t, R_t$ 의 조건수가 매우 크기 때문에 두 방법 모두 double precision 으로 계산될 필요가 있으나, 계산량이 매우 많아질 것임
3.3 Deploying on current ML infrastructure
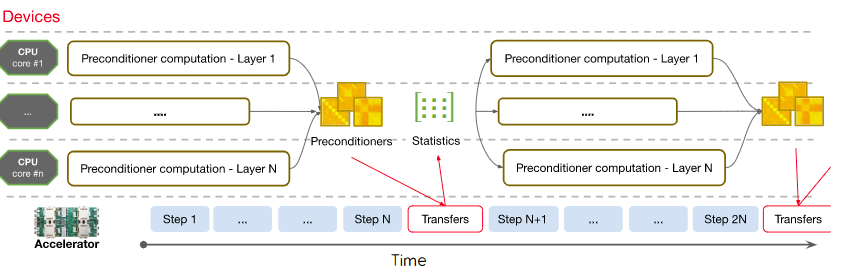 Fig 1. 병렬화된 Shampoo 의 계산 다이어그램
Fig 1. 병렬화된 Shampoo 의 계산 다이어그램
Heterogeneous training hardware. 가속기 설계의 방향은 주로 낮은 precision 이지만, double precision 계산이 다수의 레이어에서 수행되어야 했고, 따라서 가속기보다 CPU 들을 활용하였음
API inflexibility. 제안하는 방법이 비표준적인 학습 과정을 따르므로 framework 수준의 변경이 필요했고, Lingvo TensorFlow framework 을 사용하엿음
4 Distributed Systen Design
- 표준 병렬화에서는 parameter 가 각 가속기 코어에 복제되어 forward & back propagation 을 수행하고, 다시 한 곳으로 모여 배치에 대해 평균됨
- Preconditioner 의 inverse pth root 는 double precision 이어야 하지만, 수 백 스텝마다 비동기적으로 계산되므로 CPU 를 사용할 것임
- 각 레이어마다 Preconditioner 를 계산하므로 여러 CPU 에 계산을 분산시킴 (Fig. 1)
5 Experiment
5.1 Comparison of second order methods
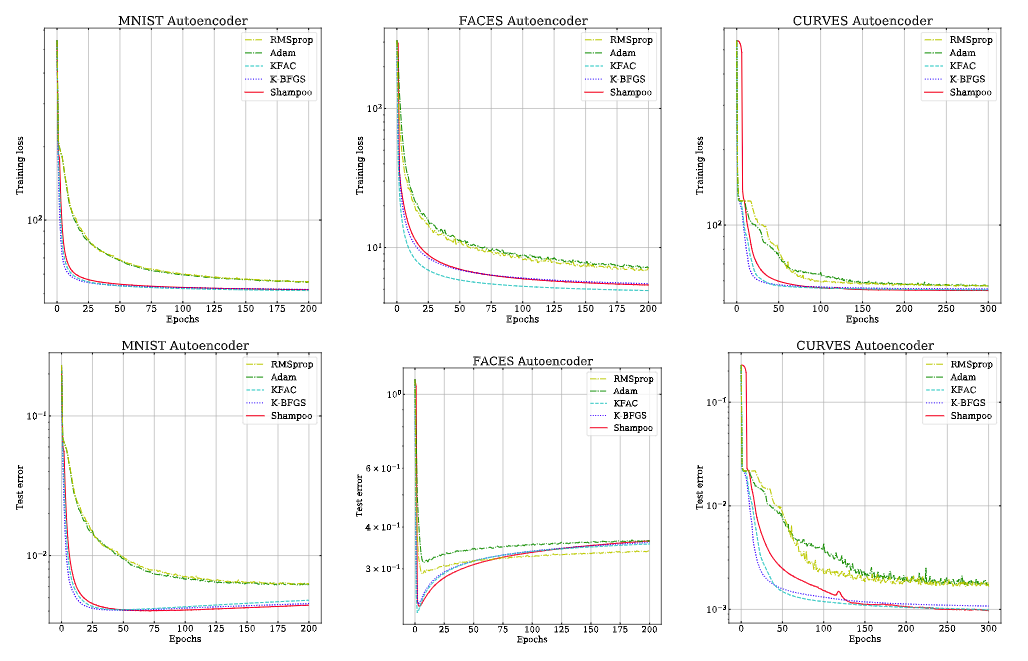 Fig 2. Autoencoder 문제에서 여러 2차 최적화 방법과 비교
Fig 2. Autoencoder 문제에서 여러 2차 최적화 방법과 비교
- Autoencoder 문제를 두고 K-FAC, K-BFGS 와 비교하였으며, 모든 알고리즘의 결과가 유사했음 (Fig. 2)
5.2 Machine translation with a transformer
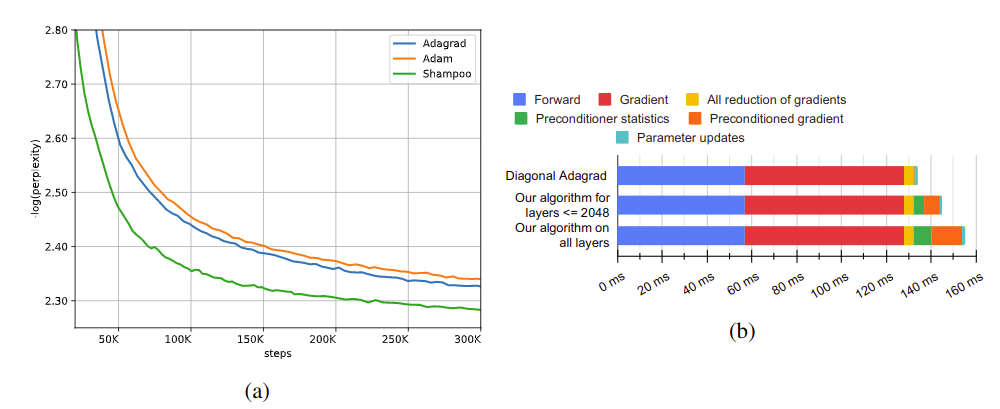 Fig 3. 기계 번역 문제에서 비교 결과로, 모든 계산은 CPU 로 수행하였
Fig 3. 기계 번역 문제에서 비교 결과로, 모든 계산은 CPU 로 수행하였
- 영어의 불어 번역 데이터 WMT’14 의 36.3 문장 쌍을 Transformer 구조(93.3M) 학습하고, Adagrad 와 Adam 과 비교함
- ~ 60 % 느린 계산 속도를 보였지만 1.95x 빨리 수렴하였으며, preconditioner 계산을 위한 오버헤드는 분산 계산을 통해 꽤 낮아졌음을 확인할 수 있음
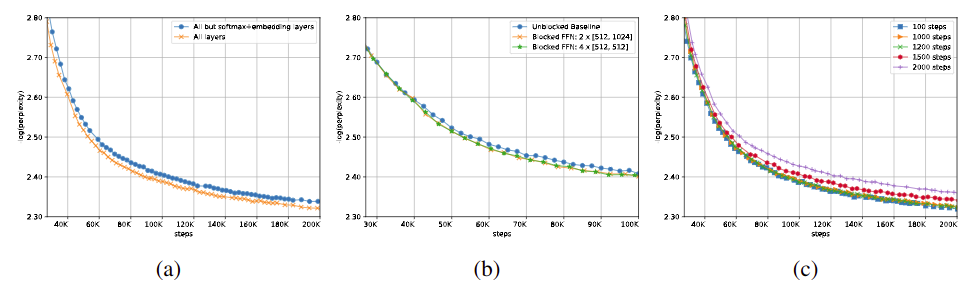 Fig 4. (a) 전체 또는 embedding 레이어에만 적용했을 때, (b) 여러 블락들로 근사했을 때, (c) precondtioner 업데이트 주기를 변경했을 때 성능 비교
Fig 4. (a) 전체 또는 embedding 레이어에만 적용했을 때, (b) 여러 블락들로 근사했을 때, (c) precondtioner 업데이트 주기를 변경했을 때 성능 비교
Preconditioning of embedding and softmax Layers
$R_t, L_t$ 중 하나만 이용하여 Precondition 했을 때 ($G_tR_t^{-1/2}$ or $L_t^{-1/2}G_t$), 6 %의 계산 시간 증가(Fig. 3b)로 20 % 수렴 시간을 줄일 수 있었음 (Fig. 4a)
Reducing overhead in fully-connected Layers
FC 레이어의 preconditioner 를 2 개 그리고 4 개 블락들로 근사하였을 때, 성능 하락은 3 % 이내였음
5.3 Transformer-Big model
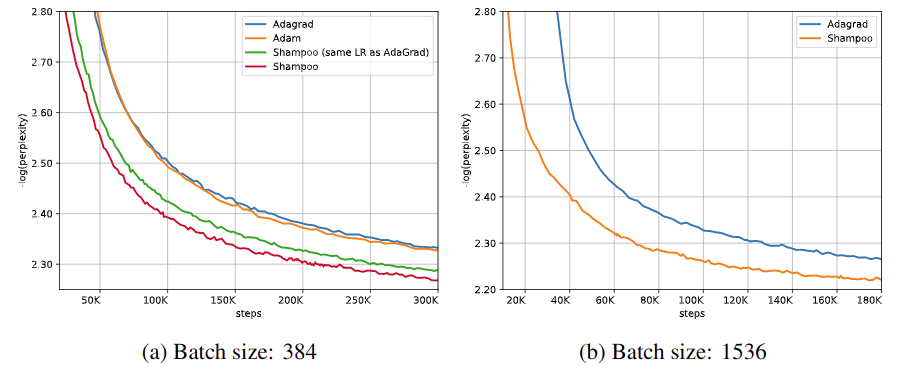 Fig 5. 번영 문제에서 최적화 방법 및 배치 크기에 따른 성능 비교
Fig 5. 번영 문제에서 최적화 방법 및 배치 크기에 따른 성능 비교
더 큰 Transformer 모델(375.4M)에 대해 비교하였을 때, 30 % 적은 계산 시간을 보였으며, 배치 크기가 클 때 이 효과가 더 두드러
5.4 Ads Click-Through Rate (CTP) Prediction
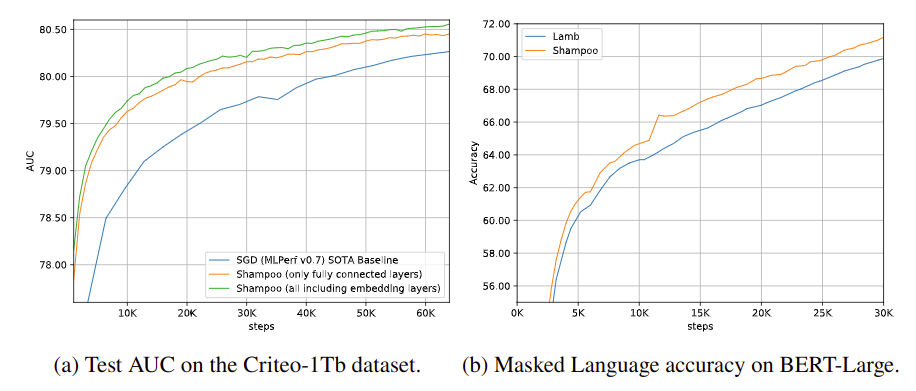 Fig 6. CTP 예측 문제, 언어 모델링 문제에서 Shampoo 의 성능
Fig 6. CTP 예측 문제, 언어 모델링 문제에서 Shampoo 의 성능
광고 클릭 데이터셋에 대한 딥러닝 추천 모델을 학습시킬 때 제안한 방법을 이용하였고, 0.3 % AUC 개선된 SOTA 성능을 보였고, 총 스텝 수도 39.96K 에서 30.97K 로 감소시켰음 (Fig. 6a)
5.5 Language modeling
- Bert-Large 모델(340M)을 (a) 주변으로부터 가려진 토큰 찾기(MLM) (b) 다음 문장 예측하기 문제(NSP)에 대해 학습시켰음
- MLM 문제에서 16 % 적은 스텝 수로 1 % 성능 향상을 보였음
5.6 Image classification
ResNet-50 모델을 이용한 ImageNet-2012 분류 문제를 해결할 때, Nesterov momentum 혹은 LARS 최적화 방법을 사용했을 때보다 적은 수의 스텝으로 75.9 % 의 정확도에 도달하였음
6 Concluding Remarks
- 딥러닝을 위한 2차 최적화 방법을 구현 방법을 제안하였고 스텝 시간과 wall clock 에 있어 향상된 성능을 확인함
- 기존 구현 대부분이 대칭 행렬을 이용하지만, 대칭 연산자를 이용하는 경우는 발견하지 못했는데, 이는 플롭과 메모리를 약 50 % 절약할 수 있음
- 섞인 precision 을 사용한다면 preconditioner 계산을 더 자주 수행할 수 있을 것임