[정리] MIER: Meta-Reinforcement Learning Robust to Distributional Shift via Model Identification and Experience Relabeling (ICML Workshop, 2020)
03 Apr 2022Author: Russell Mendonca, Xinyang Geng, Chelsea Finn, Sergey Levine Paper Link: https://arxiv.org/abs/2006.07178 Talk in NeurIPS2020 Workshop: https://slideslive.com/38931350/ Code: https://github.com/russellmendonca/mier_public.git/
요약
- Off-policy meta RL 에서 태스크가 Out-of-dist 일 때 외삽이 가능하도록 dynamics/ reward 모델을 meta 학습함
- 시험 태스크 경험이 주어지면 context variable 을 meta 학습 방식으로 적응시키고, universal policy 에 이용함
- 외삽 성능을 높이기 위해 학습한 모델로 가상의 경험을 생성하여 policy 학습에 이용함
0. Abstract
- 여러 태스크를 수행하려 할 때, 다양한 스킬들을 학습하는 것은 많은 수의 샘플이 요구됨
- Meta RL 은 선험지식을 이용해 빠르게 적응(adapt)하지만, 시험 태스크가 학습 태스크들에 얼마나 가까운지에 따라 결과가 상이함
- On policy 처럼 많은 샘플 없이 시험 태스크를 해결하는 것, 즉 효율적인 외삽(extrapolate)을 목표로 함
- Dynamics 모델 식별(identification)과 경험 재분류(experience relabeling) 과정으로 목표를 달성하는 방법 MIER 를 제안함
- 모델 학습은 적은 off policy 샘플로 가능한 것에서 착안한 것으로, 시험 태스크에서 학습한 모델을 이용하여 policy 와 value 를 학습함으로써 Meta RL 없이 외삽 수행함
1. Introduction
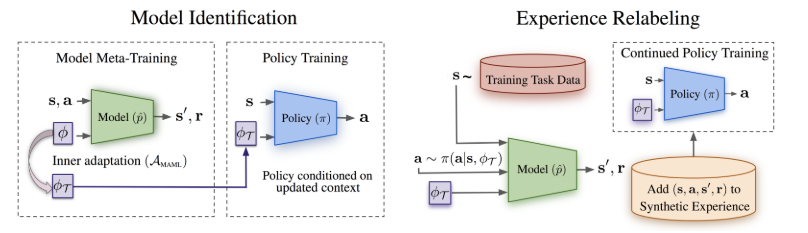 Fig 1. Meta RL 에서의 모델 식별과 경험 재분류 방법
Fig 1. Meta RL 에서의 모델 식별과 경험 재분류 방법
모델 인식에서 얻은 context variable 과 시험 태스크의 샘플를 이용하여 가상의 경험을 만들고 이로부터 policy 를 학습함
- 선험 지식을 이용하여 새 태스크를 빠르게 학습하는 Meta RL 은 대부분 많은 수의 on policy 샘플들이 요구되었음
- Off policy 기반의 value 를 meta 학습하여 policy 를 학습시키는 것은 계산량이 많아 어려움 (Appendix D)
- 대신 dynamics/ reward 모델과 context variable 을 meta 학습하고 이를 이용하여 policy 와 value 를 도출하는 것으로 meta RL 을 수행할 것임
- 태스크 정보를 담고 있은 context variable 은 모델의 입력이며, gradient descent 를 이용하여 각 태스크에 적응되어 policy 입력이 됨 (Fig. 1)
- Policy 학습은 context variable 이 state 에 추가됨을 제외하면, standard RL 과 다르지 않음
- 시험 태스크의 context variable 이 상이하면 policy 성능에 문제될 수 있는데, gradient descent 방식으로 모델 적응시키고 이로부터 얻은 가상 경험으로 policy 학습하는 경험 재분류 방법 사용함 (Fig. 1) (시험 태스크 샘플로 context variable 을 meta learning 방식으로 적응시켰다는 말)
2. Preliminaries
- Meta RL 은 표준 RL 에 더하여 태스크 분포 $\rho(\mathcal{T})$ 를 가지며 아래와 같은 목적함수를 최대화함
단, 시험 태스크에 대해서 policy 의 적응을 위해 $D_{adapt}^{(\mathcal{T})}$ 를 수집함
- Dynamics 모델의 meta 학습은 MAML을 따르며, $D_{adapt}^{(\mathcal{T})}$ 을 이용해 적응한 모델의 $D_{eval}^{(\mathcal{T})}$ 에 대한 손실함수를 이용함 (즉, 적은 데이터로 빠르게 적응해 평가 데이터에 대한 성능을 올리도록 유도함)
- 적응을 나타내는 $\mathcal{A}(\theta,\mathcal{D}^{(\mathcal{T})}_{adapt})$ 을 one step 버전으로 나타내면 아래와 같음
적응의 업데이트 방식은 경사 하강법과 같기 때문에 $\rho(\mathcal{T})$ 와 무관히 모델 정확도의 향상이 이뤄짐
3. Meta Training with Model Identification

- Meta 태스크 식별 문제를 dynamics 와 reward 모델의 meta 학습 방법으로 해결함
-
Dynamics 모델 $\hat{p}(\mathbf{s’, r s, a};\theta,\phi)$ 은 적응 중 각 태스크의 정보를 담고 있는 latent context variable $\phi$ 로 표현됨 - 적응 시에는 meta 학습으로 오직 context variable 만을 적응시키고 이를 universal policy 에 적용하여 meta RL 을 수행함 (Alg. 1)
- 모델 학습 시 손실 함수는 음의 로그 확률 $-\log{\hat{p}(\mathbb{s’,r|s,a};\theta{},\phi{})}$ 이고, context variable 의 적응 과정 중 gradient 스텝은 아래와 같음 \(\begin{aligned} \phi{}_\mathcal{T}&=\mathcal{A}_\text{MAML}(\theta{},\phi{},\mathcal{D}^{(\mathcal{T})}_{adapt}) \\ &=\phi{}-\alpha{}\nabla{}_\phi{}\mathbb{E}_{\mathbb{(s,a,s',r)}\sim\mathcal{D}^{(\mathcal{T})}_{eval}} [-\log{\hat{p}(\mathbb{s',r|s,a};\theta{},\phi{})}] \end{aligned}\)
- 모델 학습의 meta 손실 함수는 다음과 같은데, 적응된 context variable $\phi{}_\mathcal{T}$ 가 사용됨 \(\arg{}\min{}_{\theta{},\phi{}}J_{\hat{p}}(\theta{},\phi{},\mathcal{D}^{(\mathcal{T})}_{adapt}\mathcal{D}^{(\mathcal{T})}_{eval}) \\ =\arg{}\min{}_{\theta{},\phi{}}\mathbb{E}_{(\mathbb{s,a,s',r})\sim{}\mathcal{D}^{(\mathcal{T})}_{eval}} [-\log{\hat{p}(\mathbb{s',r|s,a};\theta{},\phi{}_\mathcal{T})}]\)
- 평가 데이터에 대해 시작 context variable 은 빠르게 적응하도록, 모델 파라미터 $\theta{}$ 는 적응한 $\phi{}$ 를 받아 정확도를 높이도록 최적화가 이뤄짐
- Off-policy Meta RL 방법인 PEARL 에서 외삽도 가능하도록 context variable $\phi{}$ 을 적응하도록 확장한 것이며, ${\phi{}}$ 가 out-of-dist. 일 때를 위해 경험 재분류를 이용함 (Section 4)
- Policy $\pi_\psi$ 는 context variable 을 추가 state 로 받는 universal policy 이며, 표준 off-policy RL 방식인 SAC 으로 학습됨 \(J_\pi{}(\psi{},\mathcal{D},\phi{}_\mathcal{T})= -\mathbb{E}_{\mathbf{s}\sim{}\mathcal{D},\mathbf{a}\sim{}\pi{}} [Q^{\pi{}_\psi{}}(\mathbf{s,a},\phi{}_\mathcal{T})] \\ \text{where}\quad{}Q^{\pi{}_\psi{}}(\mathbf{s,a},\phi{}_\mathcal{T})= \mathbb{E}_{\mathbf{s}_t,\mathbf{a}_a\sim{}\pi{}} [\Sigma{}_t\gamma{}^tr(\mathbf{s}_t,\mathbf{a}_t)| \mathbf{s}_0=\mathbf{s},\mathbf{a}_0=\mathbf{a}]\)
4 Improving Out-of-Distribution Performance by Experience relabeling

- 적응한 context variable 이 policy 에게 out-of-dist. 이면 성능이 저하되므로, dynamics/ reward 모델을 이용하여 가상의 경험을 만들고 policy 를 학습시키는 경험 재분류 방법을 이용함
- 기존 다른 태스크들의 경험을 이용하여 가상 경험을 만드는데, time step 이 길면 에러가 누적되어 문제되므로 한 step 만 고려함 (When to Trust Your Model)
- 경험 재분류는 기존 태스크의 경험을 Importance sampling 을 통해 이용하는 MQL 과 유사하나, 시험 태스크가 다른 분포에서 샘플되는 점이 다름
˛˛
5 Related Work
- 비모델 encoder 기반 meta RL 은 적응 중 경험을 context variable 로 전환하고 이를 universal policy 에 사용하였음
- 전환을 위해 Recurrent encoder 또는 variational inference 를 이용하였음
- Out-of-dist. 태스크에서 적응 성능이 좋지 않음
- 적응 중 경사 하강을 이용하는 비모델 meta RL 방법도 존재하나, On-policy 샘플을 이용하여 적응하기 때문에 샘플 효율이 낮음
- 모델 기반 meta RL 은 적응한 모델을 model predictive control 에 이용하는 방식이나, 대체로 낮은 성능을 보였음 (Fig. 4)
6 Experimental Evaluation
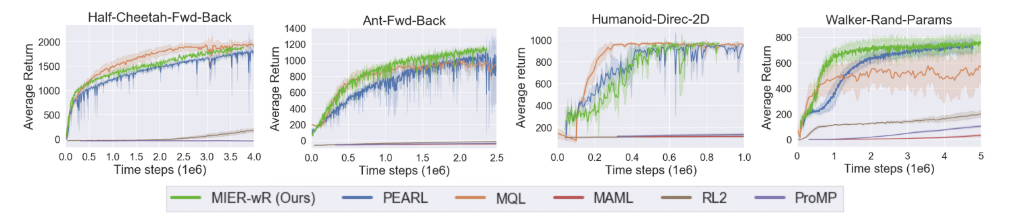 Figure 2. 외삽 평가가 없는 표준 meta RL benchmarks 에서 여러 알고리즘의 성능
Figure 2. 외삽 평가가 없는 표준 meta RL benchmarks 에서 여러 알고리즘의 성능
다음과 같은 질문에 대한 답을 얻고자 하며, Open AI gym 과 mujoco 시뮬레이터를 이용하였음 1) 표준 meta RL benchmarks 에서 효율적으로 학습하여 SOTA 에 견줄만한 성능을 보이는가? 2) 기존 meta RL 과 비교하여 시험 태스크에 대한 외삽 성능은 어느 정도인가? 3) 경험 재분류가 외삽 시 성능에 얼마나 영향을 미치는가?
6.1 Meta-Training Sample Efficiency on Meta-RL Benchmarks
- 기존 meta RL 방법인 PEARL, MQL, MAML, ProMP, MAML 그리고 RL2 와 외삽이 요구되지 않는 문제에 대해 비교하였음 (Fig. 2)
- 경험 재분류가 없을 때 MIER 의 성능도 함께 비교했을 때 (MIER-wR), 모델 식별의 meta RL 만으로도 SOTA 성능과 유사했음
6.2 Adaptation to Out-of-Distribution Tasks
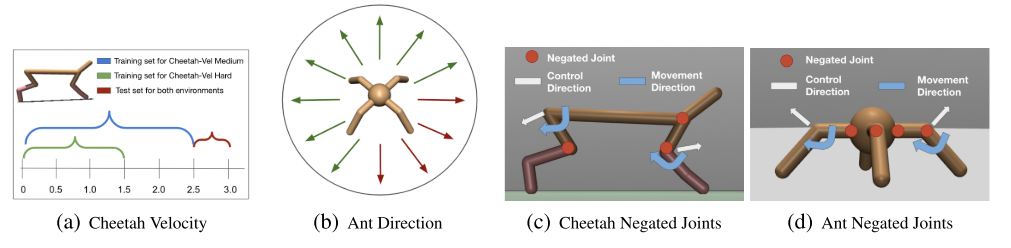 Figure 3. Out-of-dist 태스크 설명
Figure 3. Out-of-dist 태스크 설명
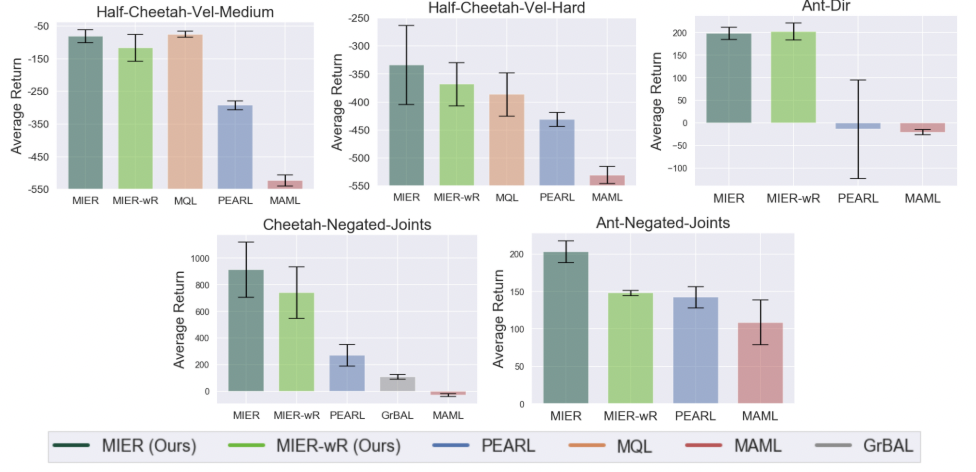 Figure 4. Out-of-dist 태스크에서 meta RL 성능 비교
Figure 4. Out-of-dist 태스크에서 meta RL 성능 비교
- 외삽은 reward 와 dynamics 에 대해 각각 고려되었으며, MIER 가 높은 성능을 보임
- Dynamics 변형은 제어 신호에 대한 움직임 방향을 반대로 하는 방식을 사용함
7 Conclusion
- 효율적인 meta RL 을 위해 모델 인식 문제로 변형하고, 외삽을 위해 경험 재분류 방법을 이용함
- 시험 태스크에 dynamics/reward 모델을 적응하고, 만들어진 가상의 데이터를 이용하여 off-policy RL 방식으로 policy 를 학습함
- 모델 인식은 meta RL 위해, 경험 재분류는 외삽을 위해 사용됨
- 외삽이 필요한 meta RL 문제에서 높은 성능을 보임